
AtScale was conceived as an independent semantic layer for data and analytics for business intelligence users. Leading BI teams use AtScale to create enterprise metrics hubs, enabling self-serve access to a consistent source of metrics that are tied to data platforms with managed data pipelines. The feature stores employed by the enterprise AI and data science community have many similarities to metrics hubs and can likewise leverage the capabilities of a semantic layer managing access to cloud data.
Feature Stores are Hot
Feature stores have been a hot topic within data science circles in 2021. It has only been 4 years since Uber publicly started talking about their ML platform Michelangelo where they defined the term feature store as a layer of data management that “allows teams to share, discover, and use a highly curated set of features for their machine learning problems.” The term, feature store, has grown in popularity, with different players in the AI/ML ecosystem rallying behind the category.
Standalone startups are pushing their visions for what constitutes a feature store. Cloud data platforms and AutoML platforms are partnering or building their own feature store offerings. Despite the hype, the category is still relatively new and the majority of enterprise data science programs are only starting to formalize feature store strategies. Gartner puts Feature Stores at the most nascent position in their Hype Cycle for Data Science and Machine Learning.
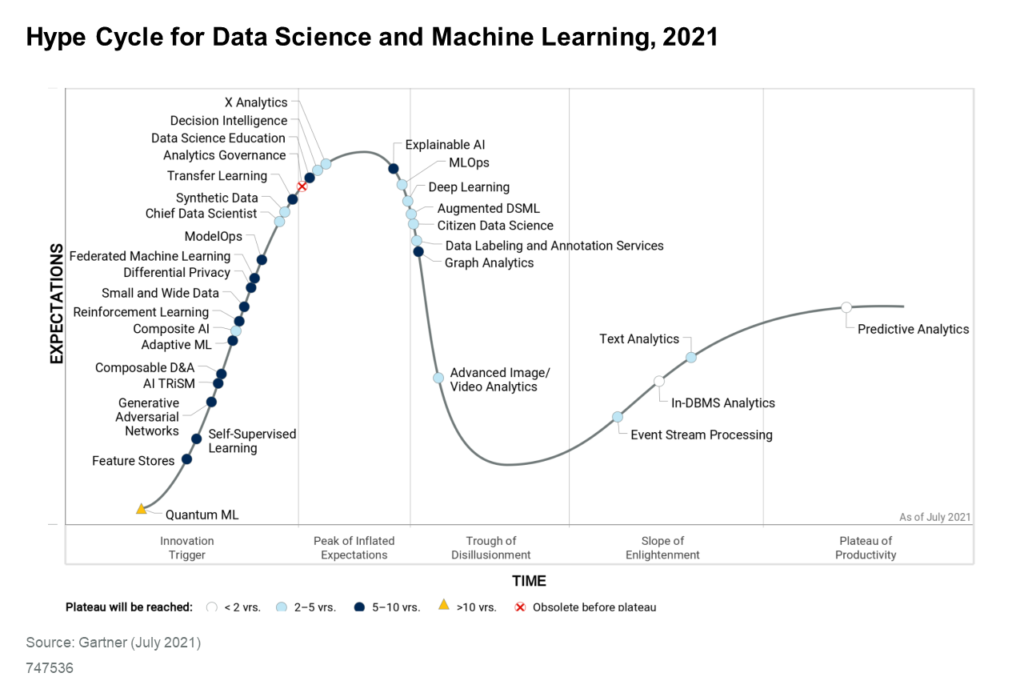
AtScale has been working with customers and advocating for the use of a semantic layer to bridge the gap between AI and BI. We introduced AI-link as a utility for data scientists to interact with an AtScale semantic layer with native Python connectivity. This enables data scientists to source features from the semantic layer into models managed in Jupyter notebooks, ML pipelines, or AutoML platforms. This post delves into the potential for leveraging AtScale to build enterprise feature stores.
Basic Functions of a Feature Store
The feature store category is still taking form – with great community involvement from groups like featurestore.org and influence from leading-edge teams like Uber’s Michelangelo, AirBnB’s Zipline, and the open source project Feast. While there is no formalized set of capabilities that constitute a full-function feature store, there are some basics that everyone agrees on:
- Feature curation. Feature stores represent a governed set of features drawing on a wide range of data – first party data from enterprise applications, second party data shared by partners, and third party data acquired by data providers.
- Simplify access to curated set of features. Data scientists spend too much time data wrangling. By exposing a pre-built set of features, data scientists can focus on model development and implementation, relying on data teams to manage the data pipelines feeding feature stores and the curation of individual features.
- Feature discoverability & reusability. A feature store should enable data scientists to easily search available features. The ability to reuse features already developed saves time and ensures consistency across models and teams.
- Manage feature lineage. Data teams need to be able to track lineage of features in order to evaluate the impact a change to underlying data may have on production models. Furthermore, as features are re-used, it is important to know which models are using a given feature.
- Harden data pipelines for production models. Beyond impact analysis using lineage analysis, it is important for production models to be insulated from changes to underlying data. A well-managed feature store can serve as a buffer from changes to raw data sources. Snapshotting of features at is important for reproducibility analysis.
- Feature serving. Features stores serve data to both training and production models. Managing performant access to features as well as managing the updating of features (in real-time or near real-time) is important.
Feature Engineering with AtScale
Ben Taylor, Chief Evangelist for DataRobot, says “Smarter features make smarter models.” In a recent conversation, he talked about the importance of getting subject matter experts (SMEs) to engineer features that make sense for the business. “Smarter features can lead to better ‘alpha, or prediction quality. In addition to more lift, smarter features can also lead to better storytelling and more actionable insights for the SMEs.”
Feature engineering is the transformation of raw data into features that represent business drivers in the format that models can work with. Simple features may be direct metrics (e.g. sale quantities) or categoricals (e.g. geography) extracted directly from raw data sets. More complicated features may be based on numerical calculations (e.g. gross margin = revenue – cost / revenue),categorizations (e.g. bucketing towns into states), or standardizations (e.g. standardizing date expressions). Time relative features (weighted averages over different time windows or period-to-period changes for different time lags) are commonly engineered for time series models.
AtScale incorporates a modeling platform that lets users easily create and publish calculated metrics and dimensions for use in BI metrics dashboards and/or as features for ML models.
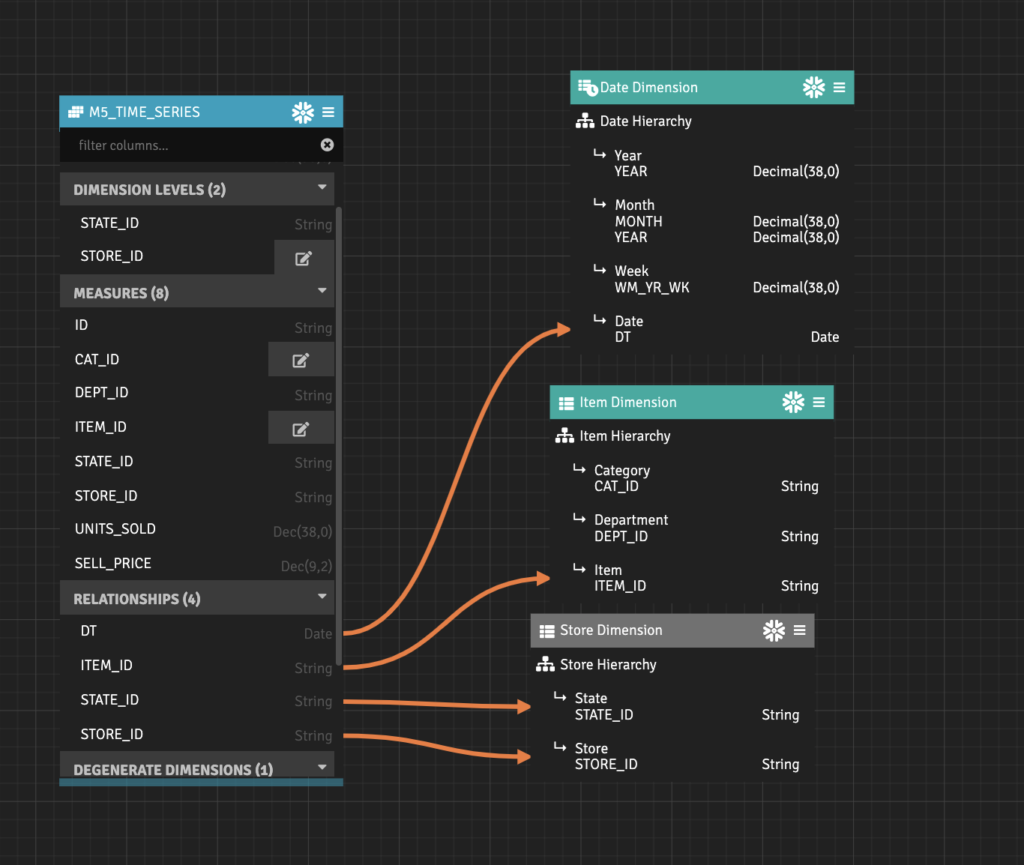
Feature Investigation with AtScale
Daniel Gray, Vice President of Systems Engineering at AtScale, talks often about how a semantic layer can help scale enterprise AI programs. Daniel told me, “We are seeing customers pushing to break down the silos separating data science teams from broader business. We see cohesive teams including data science, ML ops, Devops and Business Intelligence being build around specific business initiatives. Project owners, the business, and executives are held accountable for the performance of the machine learning/AI initiatives.”
A key technical enabler of this kind of cross-functional collaboration is making it easier to discover available features. While many data science projects may start with an exploratory analysis of raw data, feature stores that support investigation can help accelerate the development of production models.
AtScale facilitates feature investigation in a few important ways:
- Features maintained in AtScale can be catalogued in a feature library or data catalog.
- Data in AtScale can be quickly visualized using popular BI platforms or Excel.
- Data scientists can expose the full set of features in an AtScale model through a simple python interface.
Analytics discoverability is key to self-service analytics. As such, AtScale has made it simple to investigate and explore data modeled within a semantic layer.
Feature Serving with AtScale
John Lynch, the lead architect of AtScale AI-Link, has long championed the potential of exposing a universal semantic layer to data science users with bi-directional python connectivity, “The idea is to build a resilient foundation for delivering feature data to ML models, with whatever recency and performance required.”
AtScale presents data consumers with a semantic model that is connected to data live in the cloud. As metrics are requested from BI platforms or python, AtScale virtualizes queries to raw data sources and optimizes performance for users. This approach of abstracting the view of data that consumers see from the raw data can be leveraged to simplify and harden data pipelines. If there are changes in the raw data, data teams can manage at the model level in order to protect the integrity of the user’s experience.
The same capability can be used when using AtScale to serve features to data science users. Features are defined using AtScale’s modeling utility – creating a virtual definition that is linked to raw data sources. Using AtScale AI-link, features can be pulled from the semantic layer via Python. As AtScale serves features, it manages complex query logic to underlying data while ensuring high performance. While AtScale would not be used for serving real-time or streaming features, it is highly capable of serving features based on enterprise application data.
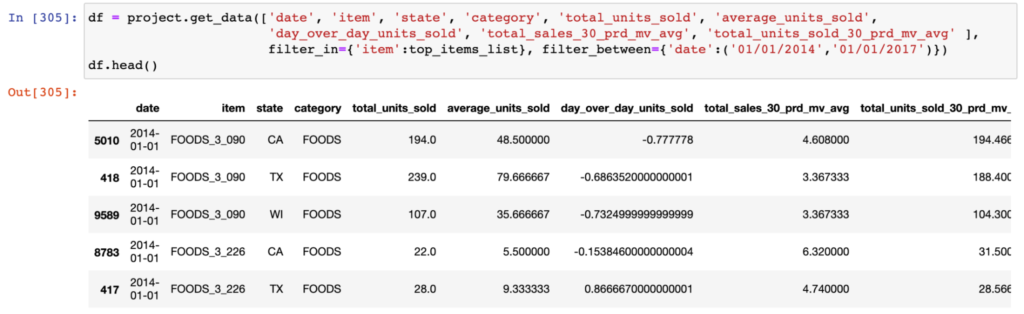
AtScale integrates with popular cloud data platforms including Microsoft Azure Synapse SQL, Google BigQuery, Amazon Redshift, Snowflake, and Databricks. The ability to serve features with live connections to enterprise data warehouses simplifies data pipelines and ensures more consistent views of data.
Feature Governance with AtScale
Dave Mariani, founder and CTO at AtScale has written extensively on how Analytics Governance Empowers Self-Service. As feature stores become more mature and widely used in an organization, the subject of governance becomes more important. Proper governance is fundamental to delivering consistency and reliability for data consumers. Governance goes beyond security and access control. It also includes managing definitions and ensuring consistency across related features.
AtScale’s semantic layer is commonly used to establish the governance required to enable self-service analytics. The governance that is appropriate for an enterprise metrics hub supporting business intelligence teams is similar to that appropriate for managing a feature store.
Beyond Feature Stores: How a Semantic Layer Drives Business Value from Enterprise AI
AtScale provides a way for organizations to build out feature stores while supporting other data consumers with a centralized enterprise metrics hub. Beyond simplifying data pipelines and ensuring consistency in the way data is consumed by data science teams, an AtScale semantic layer bridges the disconnect between AI initiatives and business outcomes..
AtScale’s AI-Link can be used to automatically write predictions (e.g. insights) back to data platforms within the same semantic layer construct. This means that model outputs are immediately available for decision-makers to leverage in the same dimensional structure they would navigate historical data – drilling up and down on time, geography, product, or whatever hierarchical structure is available. Further, model-generated insights are consumed in the same dashboards and BI tools used for descriptive data analysis.
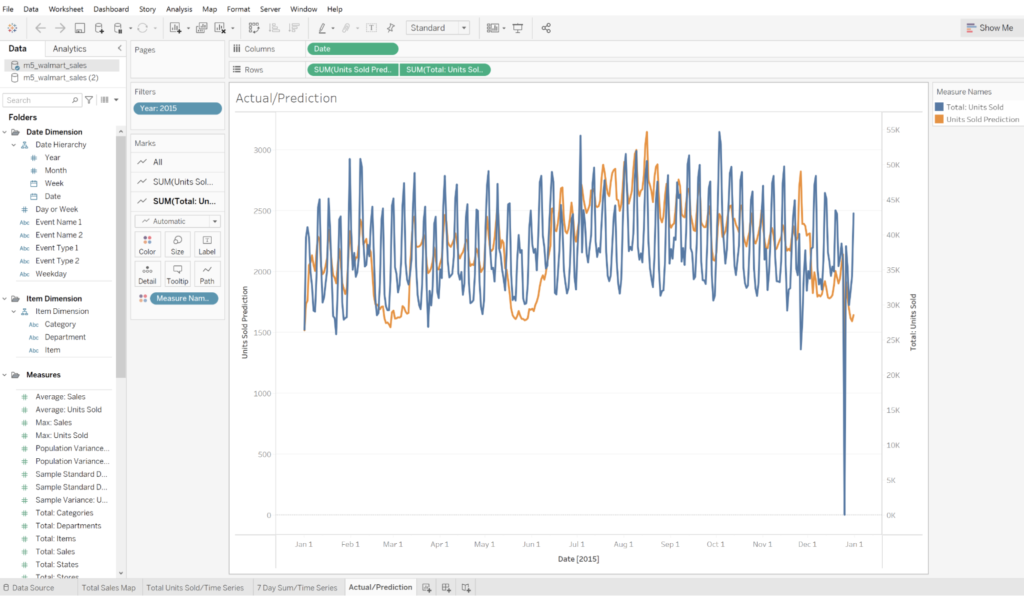
Feature stores are the data science equivalent of enterprise metrics hubs for business intelligence programs. The concept of a semantic layer is consistent across both use cases and the AtScale platform can be readily applied to both – independently or in concert.
SHARE
ANALYST REPORT