This post written by Zach Eslami in collaboration with Jeff Curran.
Storytelling is an art and a skill. Any good storyteller knows it’s always tricky finding that sweet spot to explain a concept so that it’s detailed, but doesn’t overwhelm. A story must be succinct without oversimplifying, yet still be well-understood by the listener.
This is a perpetual challenge in data analytics as the full spectrum of data teams: data analysts, data engineers, data scientists contribute different aspects of context, external/internal considerations, and approaches to deriving insights. We see this especially among data scientists: those supporting internal functions as much as those supporting end customers. They need relatable stories to provide context for data, define what is needed to solve a business problem, and to help others understand the results of their experimentation.
AI teams are being held to higher standards. Companies want to see there is an ROI from ML initiatives, so it’s crucial that more ML models get used in production environments on live data. But decisions to move anything into production are made by leadership in business and IT. Therein lies the problem: how does a data scientist communicate the value of their model, but also work with leadership understand the meaning of model inference as it pertains to data compliance and business objectives? At the end of the day, data scientists need to tell an easy to understand story, otherwise their model and work won’t make it into production.
Data Scientists Still Struggle with Access to Data, Data Preparation and Exploration
Getting access to real, meaningful data is still a challenge for data scientists. Datasets are large and often missing values. Data wrangling, exploration, and cleaning often take up a majority of a data scientist’s day (the 80/20 paradigm still exists). On many teams, data scientists have become de facto data engineers who make a copy or take an extract of the overall data because the real dataset is too large to be loaded into a dataframe for use within a notebook on their local machines.
From a traditional business perspective, data is data; as long as there is a mechanism to effectively capture and store it, an analytics team should be able to quickly derive meaningful insights to help guide decision making. But this is hardly ever the case, and it causes friction among data scientists and with their constituent partners. There is external pressure to move quickly to get to the end goal: the insight. When this happens, key data preparation steps needed for model training are often rushed or skipped. This could include data wrangling, imputation, scaling, partitioning, exploration and more.
AutoML has helped to commoditize model creation and training, but any resulting algorithm is based on the underlying data provided by the data scientist. At best, this can lead to messy data sets or incorrect feature selection; at worst this can lead to incoherent, biased, drift-prone models leading to incorrect predictions, implicating large scale business decisions. So regardless of the ML framework or tool, data scientists need to continue to invest their time in properly managing their data to better curate the proper pipelines for all aspects of analytics.
Data Scientists Continue to Operate in Silos from Other Teams
Presented with a mix of questions, problems, and concerns, data scientists are expected to work with teams of subject matter and data experts on a wide spectrum of projects. This can cover everything from BI dashboards, to evaluating and conducting Exploratory Data Analysis (EDA) on new data sources, to creating ML models for predictive or descriptive insights. Even in supporting function roles (for example, a data scientist supporting a marketing team to determine which and when to deploy new product campaigns), there is still an expectation that data scientists should be able to understand a problem, its contributing data source(s), and quickly derive a solution.
Like any science, data science solutions often depend on a number of assumptions. Without clear lines of communication to validate these assumptions, days or weeks of work can be wasted developing models that are not usable to the business. For example, let’s imagine a data scientist who was given two years of sales data to generate a predictive model for a company who wants to know future daily sales of products in different stores. Unbeknownst to the data scientist, there was a regional supply chain issue two years ago that affected a number of stores in the weeks surrounding the holiday sales rush. When this issue is resolved the following year, it results in a return to historically average revenue, but a significant increase from the year prior.
With limited access to the larger set of data to see this, the data scientist is likely going to infer feature definitions that may not match with what the business is using to interpret data. For example, a business analyst and a data scientist may create a feature accounting for the number of sales of product per month, avg_sales_per_month, but when they review the data the corresponding values a data scientist uses as the training data for an ML model may be very different than what the business analyst had been using — creating distrust from the business about what the data scientist is doing.
Even just the manner in which data is displayed in different tools can cause some friction among different data roles; business analysts may be comfortable in various BI tools, but if a data scientist creates a Matplotlib chart that displays the same data in a different way, the business analyst is much more likely to disregard the data scientist’s work.
Access to the right context of data across data analytics and business teams is crucial for successful data science projects. There are some new concepts emerging, such as a hub-and-spoke federated data management and policy organization¹ and feature stores, which foster transparency to data lineage and artifacts while allowing individual teams to create data models that support their specific functions. However, data scientists will still need support from the subject matter experts to help guide data pipeline, modeling, and model optimization decision-making.
Data Scientists Use MLOps Techniques for Model Performance…. Not Business Strategy
Once context is sorted, and datasets are adjusted and well understood, the data scientist is brought to the forefront of the conversation to train, serve, and present model output to the business. This often creates another divergence in interpretation of model meaning.
After weeks or months of preparation, training, and integration, a model may be placed in a pilot production environment (though this still only happens with a negligible amount of overall initiatives² due to friction from the aforementioned silos and interpretation of data, around 90% of machine learning models never make it). With AI-Link, data scientists can write back model predictions and metadata to the data warehouse in a schema that can be consumed by business intelligence tools. So as data and business teams come together to determine what to do next with this ML modeling experiment, the data scientist can justify their model performance and instill confidence in moving the model to production knowing that it is aligned with the objectives of the business.
Another layer of complexity is the growing relationship between data scientists and IT or compliance departments. Let’s assume now this model is appropriately re-trained to be performant and aligned with the business. There still needs to be a clear story about what happened within the model to yield a particular output. This provides an explanation for the business to maintain confidence in the investment and offers a level of trust for the compliance team that the data flow for the model is being managed within the company regulations. As data scientists aim to move models from experimentation to pilot to production environments pursuant DevOps processes shift as well in order to ensure the data, model, integrated systems, downstream consumers, etc. have been approved by a team that likely had not to this point had any exposure to the project. This then adds time and frustration to the model creation process to ensure everything is compliant.
Both of these issues in turn create further divergence again among the data teams managing and interpreting models designed to solve a problem. We end up with super accurate models (or continued concerted investments to make the model more ‘performant’), but no new answers and continued friction among the teams.
At the end of the day, there needs to be a way for data scientists to use the same interpretation of data and same definition of metrics that the business is using in order to justify the predictions from their model in an easily understandable matter so their models can be moved to production (and the business can make the right decisions based on live data).
AI Link: Empowering Data Scientists with the Power of the Semantic Layer.
Here at AtScale we understand the important role data scientists have in helping influence the right decisions for the business. We want to help data scientists be more successful by getting their models into production where they will be used by company stakeholders to make decisions to optimize the business’s bottom line and craft strategic differentiation in the market. Our product, AI-Link takes advantage of the AtScale semantic layer to address the core issues discussed earlier in this blog and offers a new mechanism to transform the modern analytics stack with machine learning.
Access to Real Data and Faster Data Preparation Timelines
AI-Link helps to facilitate programmatic data exploration, dataset manipulation, and feature selection to turn months of work into mere hours of work without duplicating or moving data from its source.. With AI-Link, users can interact with the AtScale semantic layer to persist the appropriate hierarchies, dimensions, and filters for all data input/output all within the data warehouse. By doing so, data scientists are more effectively able to access real data as data frames that can be used within their notebook for modeling. AI Link also offers a way for data scientists to store their features within the AtScale platform or with third party feature store vendors like Feast³.
No More Siloed Data Teams
AI-Link is a python-based orchestration layer that leverages the AtScale semantic layer to provide a logical view of data adjoined with features defined in the language of the business. Data scientists, data analysts, and aata engineers can work more effectively and efficiently together to identify qualities of data and resultant attributes grounded in metrics that matter to the business so that any created prediction model is performant and aligned with business objectives from the start.
MLOps with Business Input
AI Link enables the data scientist to not only serve features to downstream ML framework or applications, but also allows them to retrieve and serve insights back to the data warehouse, to the logical data model layer (ex. in AtScale’s semantic layer), and to business intelligence platforms. This allows data teams to:
- Data Engineers can manage all elements of their data and constituent policies/governance in the data warehouse location of their choice. This allows existing toolchains, pipelines, and compliance standards all to be well-maintained and with a single source of truth;
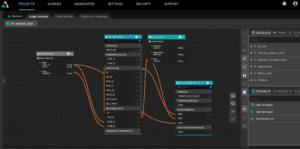
Image: Use AtScale to create uniform definitions, dimensions, and hierarchies of data and conform that to where the data is managed in the data warehouse.
- Data Scientists can append data models built primarily on historical data and analyses with ML model predictions so that multidimensional queries reflect the full spectrum of analytics, thereby bridging the gap between business intelligence and artificial intelligence;
- Business Analysts can review newly updated data models in business intelligence platforms (ex. Tableau, PowerBI, Looker, etc.) so they can present findings in a manner that allows the business to understand and ask questions to derive sound strategies. This allows data scientists to writeback predictions and also the associated metadata with those predictions (models served, feature importance reports, date/time, etc.). The dashboards that are created in business intelligence tools can now reflect model performance, model runtime explainability, and model impact, all within a channel that is understood by other members of the data team.
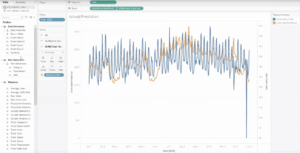
Image: Preview your data model, now appended with ML predictions in the Business Intelligence provider of your choice. Image above is rendered within Tableau.
The value proposition behind this writeback functionality is immense:
Inform Business Decisions
Data scientists will be empowered to confidently relay not only model predictions/performance, but the associated implications of the model to the business. This means that business analysts can perform correlation analysis for predicted vs. actuals to broker discussions with the data scientist to figure out what elements of the model need to be updated. This allows the two parties to discuss findings from the model and derive meaningful answers to inform the decisions the business needs to make to achieve their strategic goals.
Confidence in Ongoing Investment
Understanding begets trust, trust begets confidence; business intelligence platforms can be updated to reflect model predictions granting a full spectrum of analytics in easy-to-understand visualizations. There is no longer a barrier of understanding that oftentimes causes friction between the business and data teams. This allows the business to be confident in their ongoing capex investment knowing that this work will inform business decisions for the future state of the company grounded in the data of the business.
Greater Cost Savings, Revenue Generation
Programmatic data preparation and feature selection enables expedited model training, reducing time and associated labor cost overhead. Over months of time across even a small team of data scientists, this can yield millions in cost savings. This also means more models will be deployed in production and less time will be spent on model re-training. With those time savings, businesses can solve problems like customer churn and experiment with customer acquisition.
If you would like access to a trial of AI-Link, or have any questions, please reach out to zach.eslami@atscale.com.
SHARE
2026 State of the Semantic Layer