April 6, 2026
Best Data Governance Tools for Enterprises: 2026 GuideDefinition
In short, a Data Mesh is a framework and architecture for delivering data products as a service, supporting federated, domain-driven uses and users, and enabling decentralized insights created from centralized infrastructure configured to deliver data product components as microservices supported by governance.
It is important to note that “data mesh” is not the same as “data fabric.” “Data fabric” and “data mesh” often compete for mindshare, but Gartner defined the two as distinctly different in late 2021, stating that:
“A data fabric is the utilization of multiple existing technologies in combination to enable a metadata-driven implementation and augmented orchestration design. A data mesh is a solution architecture that can guide design within a technology-agnostic framework.”
To make matters more confusing, we see different segments of the data and analytics market each putting its own spin on the concept of data mesh. Since there isn’t a singular definition yet, let’s cover a few of the different ways that organizations choose to describe and operationalize the data mesh.
Varying definitions of data mesh from different layers of the modern data stack:
- Data Virtualization companies tend to define data mesh as a virtualization process, as in creating something that looks similar to data federation. In practice, this means different business units build analytics programs on physically disparate data sources and then centrally manage a virtualization solution that enables queries across hybrid and multiple cloud infrastructures.
- Data Governance companies, including data catalog solution providers, focus on the governance perspective. This definition of data mesh emphasizes the need to facilitate discoverability and interoperability. It’s all about giving ownership to decentralized workgroups and empowering each of them to leverage data and analytics building blocks. This way, each business unit can build its own data products on an as-needed basis.
- Data Integration and Transformation providers focus on transformation. This definition emphasizes techniques for managing the decentralization of data and analytics engineering. The goal here is to enable decentralized workgroups to manage data movement and preparation for their own analytics products.
AtScale’s Definition of Data Mesh
While the various flavors of data mesh definition are broadly consistent, they all tend to emphasize elements justifying the need for their particular solutions. So it’s our turn, as the leading provider of an independent semantic layer for data and analytics.
We see the semantic layer as an enabling technology for a data mesh strategy. Here are three of the key enabling capabilities of a semantic layer that are also fundamental to data mesh success:
- It manages the translation of analytics-ready to business-ready data by enabling your data to speak the language of your business.
- It simplifies the creation of new business-ready views with pre-built, composable building blocks.
- It is the logical place to apply governance policies that form the guardrails on data usage, ensuring consistency, compliance, and trust.
AtScale specifically ascribes to the definition of data mesh that emphasizes a hub-and-spoke analytics program: centralized governance of data assets, infrastructure, and access with decentralized data product design and creation.
Using this definition, the goals of a data mesh become:
- Defining data domains and aligning with business domains
- Combining data domains with business context to create data products
- Registering data products and making them available for re-use based on business needs
- Creating the data mesh tissue by connecting the data domains via conforming dimensions
Purpose
The purpose of the Data Mesh is to increase the speed, scale, and cost effectiveness to deliver insights to business users, focusing more on insights created by and for domain-driven use cases and users. The data mesh architecture is a modern evolution of data warehouses and data lakes (as well as hybrid data lakehouse), focusing on delivering data products and their components as a microservice to domain-focused users, focusing on decentralized insights creation.
Principles to Consider When Implementing a Data Mesh
- Enterprise data mesh includes the data and all the end-to-end analytics components as part of the data product
- Data Governance and core technology infrastructure are centralized to ensure that data and applications are governed and synchronized
- Data mesh assigns a data product to a domain (e.g. business function / area)
- Data products are created and owned by each domain. Even data that is surfaced from the existing IT infrastructure is created as a data product by the domain.
- Data Products are built and managed by the domain, and which may be shared with other domains to avoid duplication and improve productivity and consistency
- Data Products are registered (cataloged), governed and available / interoperable for inspection and reuse, including having all aspects of creation documented / shared – this includes artifacts such as table/schemas/structures, and metrics as well as data pipelines and transformations
- Creating data products by each domain (or as a group of domains) requires resources such as data analysts / business analytics expertise and BI application engineering armed with skills to be able to translate conformed data (from the data lake or warehouse) into actionable insights via data wrangling and BI tools.
- Scale is achieved by expanding the presence of data analysts / business analytics experts staffed within / across the domains
- Technology infrastructure is managed by a small team supporting the basic services required to create a data product
A visual depiction of a typical data mesh architecture is provided below:
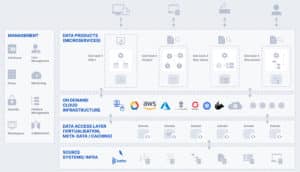
How Does an Organization Adopt Data Mesh?
The level of change that an organization must make in order to adopt data mesh depends on its relative level of data and analytics maturity. In many cases, the organizational and infrastructure groundwork for data mesh has already been laid. For instance, centralizing data assets on a modern cloud platform is a prerequisite. Likewise, the capability to transform and model data assets for delivering analytics-ready data is fundamental. For organizations that already have a robust data and analytics infrastructure, there are four basic steps needed to adopt data mesh.
1. Aligning data domains to business domains
Data mesh relies on the notion that there is a specific business group (i.e., business domain) that’s the logical “owner” of a set of data assets (i.e., a data domain). Aligning data domains to business domains sets up the basic rules of which business unit bears responsibility for curating and augmenting which data sets. Without this alignment, an organization will inevitably see conflicts between groups as they assign different significance to the same data. Without clear ownership, no one is responsible for defining the proper usage of a given data set.
2. Treating data as a product
Data as a product closely aligns with the definition of data mesh. The idea is that the business owners of a given data domain take responsibility for augmenting raw data with business context, in order to make the data useful to the broadest set of users. Business context may include basic transformations of data to make it more workable for an analytics use case. It may also include augmenting historical data with aggregation logic and hierarchical dimensional logic to support drill-up / drill-down analytics. Data products need to be created with user-friendliness in mind, laser-focused on business users’ needs. So, data as a product must include the creation of business-oriented views of data that support self-service analysis.
3. Embracing Composable Analytics and Shareability
Treating data as a product obviously means positioning data assets for direct analysis by data consumers. But it also means positioning assets for reuse in more complex applications. Domain owners should be registering data products within a catalog and making them available for reuse by other groups in the organization. Some of the most valuable data analytics inherently require blending data across multiple domains. A few examples include…
- Profitability analysis blending revenue data from a CRM system with cost data from financials
- Employee productivity blending HR data with financials
- Prediction models blending sales data with 3rd party data on the economy.
Most importantly, data products need to be discoverable and accessible by different work groups around the organization.
4. Building a Connective Tissue
Combining multiple data products managed by different business domains requires a common connective tissue. “Conformed dimensions” are governed by hierarchical master data that define how data can be aggregated. Time is the most common conformed dimension, establishing day-week-month-quarter-year logic that can be used in any data set. Other common master data concepts that often need a conformed dimension include Product, Geography, Employee, and Customer. Any work group can use conformed dimensions to combine different data assets into a new data product. Leveraging centrally governed dimensions eliminates rework and the chance for mistakes.
Primary Uses of a Data Mesh
Data Mesh is used to increase speed, scale, and cost effectiveness of delivering data, insights, and analytics across the enterprise. The data mesh framework and architecture are most appropriate when the business domains have diverse needs in terms of the data, insights, and analytics that they use, such that centralized data, reporting, and analysis are not required or beneficial. The data mesh requires the following capabilities:
- Domain-focused business ownership for insights creation
- Data analysts embedded within the domains with sufficient skills to translate confirmed data sources into Business Intelligence / Insights
- Centralized data governance, including centralized data catalogs and a semantic layer
- Centralized IT team focused on providing and supporting conforming data availability (e.g., from data lake/data warehouse)
- Centralized IT providing and supporting data product capabilities
Data Products are a self-contained dataset that includes all elements of the process required to transform the data into a published set of insights. For a Business Intelligence use case, the elements are data set creation, data model / semantic model, and published results, including reports, analyses that may be delivered via spreadsheets or BI application. Examples of data products are shown below.

Key Business Benefits of Data Mesh
The main benefit of Data Mesh is increased speed, flexibility, and scale to deliver data, insights, and analytics to business owners at the domain level. The key is for the business domain to embed the skills necessary to develop actionable insights as data products.
Challenges Associated with Implementing a Data Mesh Framework and Architecture
- Domain owns the insight creation and usage process
- Sufficient skilled resources to create insights from conformed data (e.g., data sufficiently accurate and structured to be considered useful for data integration and insights creation). This would include data analysts and BI engineers (if BI work is significant)
- Centralized data governance, including centralized data product catalogs and semantic models, is available and utilized to ensure consistency and reusability
- Centralized IT team responsible for ensuring conformed data is available and sufficient services are available to enable self-service insights and analytics creation.
- Please note that the analytics team typically remains centralized, though they are focused on self-service analytics creation with results delivered as a data product
Common Roles and Responsibilities associated with Data Mesh
Roles important to Data Mesh are as follows:
Insights Creators – Insights creators (e.g., data analysts) are responsible for creating insights from data and delivering them to insights consumers. Insights creators typically design the reports and analyses, and often develop them, including reviewing and validating the data. Insights creators are supported by insights enablers.
Insights Enablers – Insights enablers (e.g., data engineers, data architects, BI engineers) are responsible for making data available to insights creators, including helping to develop the reports and dashboards used by insights consumers.
Insights Consumers – Insights consumers (e.g., business leaders and analysts) are responsible for using insights and analyses created by insights creators to improve business performance, including through improved awareness, plans, decisions, and actions.
BI Engineer – The BI engineer is responsible for delivering business insights using OLAP methods and tools. The BI engineer works with the business and technical teams to ensure that the data is available and modeled appropriately for OLAP queries, and then builds those queries, including designing the outputs (reports, visuals, dashboards) typically using BI tools. In some cases, the BI engineer also models the data.
Business Owner – There needs to be a business owner who understands the business needs for data and subsequent reporting and analysis. This is to ensure accountability, actionability, as well as ownership for data quality and data utility based on the data model. The business owner and project sponsor are responsible for reviewing and approving the data model as well as the reports and analyses that OLAP will generate. For larger, enterprise-wide insights creation and performance measurement, a governance structure should be considered to ensure cross-functional engagement and ownership for all aspects of data acquisition, modeling, and usage: reporting, analysis.
Data Analyst / Business Analyst – Often a business analyst or more recently, data analyst are responsible for defining the uses and use cases of the data, as well as providing design input to data structure, particularly metrics, business questions / queries and outputs (reports and analyses) intended to be performed and improved. Responsibilities also include owning the roadmap for how data is going to be enhanced to address additional business questions and existing insights gaps.
Business Use Cases of Data Mesh
Data mesh empowers organizations to scale analytics while maintaining agility and governance. By decentralizing data ownership and treating data as a product, businesses address complex challenges across industries. Below are key scenarios where data mesh delivers consistent value:
Customer 360 Insights
Domain teams unify customer data from CRMs, support systems, and transactional databases into federated “data products.” Retailers, for example, combine purchase histories, web interactions, and loyalty program metrics to personalize marketing campaigns. This approach eliminates silos and fosters real-time segmentation and churn prediction without centralized bottlenecks.
Global Data Unification with Local Governance
Multinational enterprises manage region-specific compliance (e.g., GDPR, CCPA) while maintaining a global operational view. A financial institution might allow regional branches to own customer data products, with centralized governance ensuring secure aggregation for cross-border reporting. This balances autonomy with oversight and avoids costly data duplication.
Regulatory Compliance Automation
Healthcare providers and banks automate sensitive data handling using domain-specific governance. Data products auto-redact PHI or PCI data during ingestion, while lineage tracking simplifies audit trails. For instance, a hospital network applies mesh principles to share anonymized patient data across research teams without violating HIPAA.
Real-Time Analytics at Scale
Manufacturers and logistics firms leverage event-driven architectures to process IoT sensor data. Factory domains own equipment performance streams, which enables predictive maintenance alerts without overloading central systems. This reduces latency from hours to milliseconds for time-sensitive decisions.
Cross-Functional Collaboration
Organizations break down silos between departments like marketing and finance. AtScale’s semantic layer enhances this by virtualizing access to domain-owned data products, which ensures consistent metrics for BI tools and AI models. Teams collaborate on shared datasets while maintaining localized ownership, accelerating initiatives like hyper-personalized campaigns or dynamic pricing.
Data Mesh Trends and Future Outlook
Data mesh continues to spark debate as organizations weigh its decentralized approach against evolving architectural paradigms. According to Ex-Gartner analyst Malcolm Hawker, now Head of Data Strategy at Profisee, “most orgs lack the governance maturity needed to enable a data mesh, and silos and data quality issues prevail,” he said in a LinkedIn post.
Gartner’s 2025 “Hype Cycle” projections argue that the concept of data mesh may become “obsolete before plateau” as enterprises grapple with the complexity of implementation. The analyst firm suggests that while decentralized ownership addresses scalability challenges, mature organizations may revert to centralized governance models augmented by automation.
Experts like Hawker contend that Gartner is positioning data fabric (a framework emphasizing automated integration and metadata-driven governance) as the successor to data mesh. However, “if data governance maturity is a big leap for most to enable a data mesh, it’s a quantum leap to enable a data fabric,” Hawker adds. Additionally, industry practitioners like Zhamak Dehghani (data mesh’s creator) argue that real-world adoption is growing, particularly in global enterprises managing fragmented data domains.
A key trend is the convergence of data mesh and data fabric principles. Organizations are blending decentralized ownership (mesh) with federated governance and AI-driven automation (fabric). For example, retail giants now allow regional teams to manage localized customer data products while using fabric-like metadata layers to enforce global privacy standards.
Emerging innovations are reshaping the trajectory of data mesh:
- Embedded Governance – Auto-classification of sensitive data and policy enforcement at the domain level, reducing centralized oversight.
- AI-Driven Domain Curation – Machine learning identifies high-value data products and suggests cross-domain linkages, accelerating discovery.
- Synthetic Data for Collaboration – Domains share AI-generated datasets that mimic real data patterns without exposing sensitive details.
While Gartner remains skeptical of data mesh as a standalone paradigm, its principles are influencing next-gen architectures. The AtScale semantic layer platform exemplifies this evolution by enabling decentralized teams to publish governed data products while maintaining enterprise-wide consistency. By virtualizing access to domain-specific datasets, AtScale bridges the mesh-fabric divide, thereby allowing organizations to scale analytics without sacrificing security or performance. The future lies not in choosing between mesh and fabric, but in leveraging their synergies to build agile, governed ecosystems.
AtScale and Data Mesh
AtScale’s semantic layer improves data mesh implementation by enabling faster insights creation via self-service data modeling for AI and BI, including performance via automated query optimization. The Semantic Layer enables the development of a unified business-driven data model that defines what data can be used, including supporting specific queries that generate data for visualization. This enables ease of tracking and auditing, and ensures that all aspects of how data are defined, queried, and rendered across multiple dimensions, entities, attributes, and metrics, including the source data and queries made to develop output for reporting, analysis, and analytics, are known and tracked.
SHARE
Guide: How to Choose a Semantic Layer