This post was written by Donald Farmer. Donald Farmer is a seasoned data and analytics strategist, with over 30 years of experience designing data and analytics products. He has led teams at Microsoft and Qlik Technologies and is now the Principal of TreeHive Strategy, where he advises software vendors, enterprises, and investors on data and advanced analytics strategy. In addition to his work at TreeHive, Donald serves as VP of Innovation and Research at Nobody Studios, a crowd-infused venture studio. Follow him on LinkedIn.
In their day (in the twenty-teens), self-service analytics and desktop data visualization marked a true breakthrough in productivity for business intelligence analysts. Before then, those who wanted to experiment with new data or examine different configurations of existing data had to patiently make change requests with IT or do everything in Excel.
The new flexible, robust and highly usable tools cut around those limitations. They put data discovery and visualization into the hands of business users, who could work independently “with or without IT’s permission,” as one analyst said. However, these exciting capabilities brought their problems—a proliferation of analytics, duplication of effort among analysts and teams, little or no quality control and poor governance.
Today, we are in a new age. Data science, especially AI, enables even more insightful analytics than BI and the old data mining tools. AI can also automate business operations and processes and write your reports and emails.
We can’t afford to make the same mistakes again. Today’s challenge is meeting the needs of collaboration, iterative development and governance while still being productive and taking advantage of the latest breakthroughs.
AtScale has taken a new approach grounded in our understanding that the best analytics are not siloed and isolated but collaborative and iterative.
The Need for Collaborative and Iterative Analytics
Why such an emphasis on collaboration and iteration? Firstly, effective analytics rarely results from a single person’s efforts. It demands the integration of multiple skill sets and viewpoints:
- Subject Matter Experts (SMEs) bring a deep understanding of the business context, helping to frame the right questions and interpret results through a domain-specific lens.
- Data Engineers ensure the availability, quality, and scalability of the data foundation upon which analytics is built.
- Data Scientists and Analysts apply statistical techniques and modeling to extract insights and predictions from the data.
- IT and Operations teams provide the infrastructure and support to deploy and maintain analytic models in production environments.
Each of these roles contributes an essential piece to the analytics puzzle. However, enabling collaboration among these diverse stakeholders can be challenging. Traditional analytics workflows result in silos, with each group working independently and handing off their piece of the project to the next on completion. This fragmented approach often leads to misalignments, delays, and suboptimal solutions.
In practice, this traditional approach is still more complex because analytics continues to evolve in modern business. Customer preferences, market trends, and competitive landscapes can shift rapidly, requiring analytics to keep pace. What may have been a highly relevant insight or model last quarter could be rendered obsolete by new developments.
This dynamic nature demands an iterative approach to analytics that allows for continuous refinement and adaptation. Analytic models should be seen not as one-time deliverables but as living assets that evolve with the business. This requires a paradigm shift from the traditional linear analytics lifecycle to a more agile, feedback-driven process.
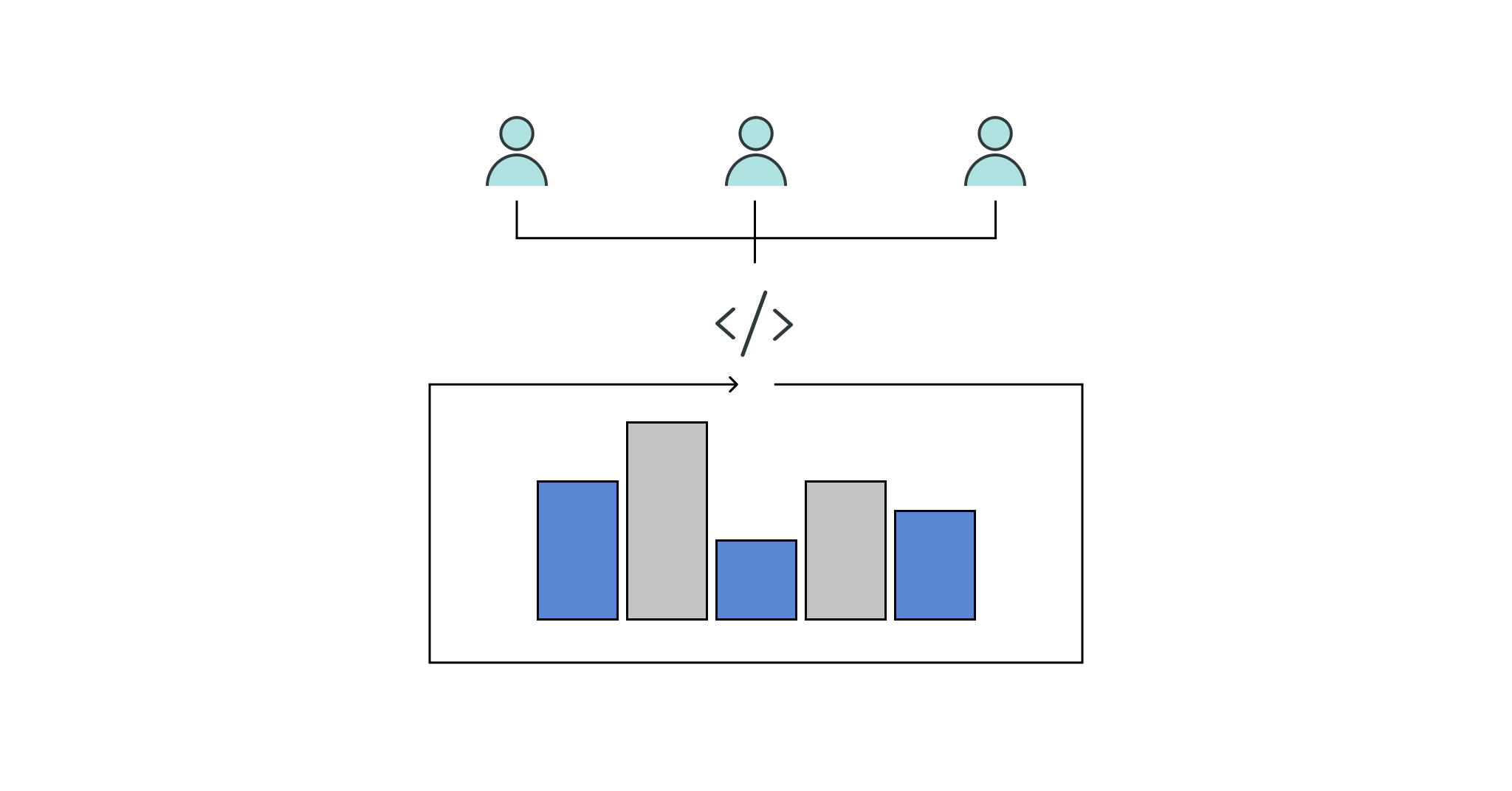
This is where AtScale’s “Analytics as Code” concept comes into play. It offers a new approach that applies the well-proven best practices of software development to the analytics domain.
Analytics as Code
The concept of “Analytics as Code” applies the principles and practices of software engineering to the analytics domain, leveraging version control systems like Git to enable collaborative, iterative, and maintainable analytics workflows.
At its core, Analytics as Code treats analytics assets as versioned artifacts. As software developers manage their codebase using Git, data professionals can manage their analytics codebase with the same techniques.
Git, the most widely used version control system, forms the backbone of the Analytics as Code approach. It provides a distributed architecture that allows multiple users to work on the same code without the risk of overwriting each other’s changes. With Git, each user has their own local copy of the repository, which they can work on. Changes are then committed to their local repository, creating a new codebase version. These changes can be pushed to a remote repository, making them available to other team members.
One of Git’s key strengths is its branching model. Branches allow team members to work on different features or experiments concurrently without affecting the main codebase. This is particularly valuable in analytics, where data scientists may want to try different modeling techniques, or data engineers may need to refactor data pipelines.
This ability to branch and test is one of the significant advantages of this approach for analytics. For example, a data scientist could create a new branch to experiment with a new machine-learning algorithm. At the same time, another team member works on developing the product dimension and hierarchies to reflect differences between regional product catalogs. Once the work on a branch is complete and validated, it can be merged back into the main branch, making it part of the official codebase.
This branching model also facilitates collaboration among diverse teams. Subject matter experts can provide input on business requirements through user stories or feature requests, which can be tracked using Git’s issue-tracking capabilities. Data engineers and scientists can then work on branches to address these requirements and submit their changes for review using pull requests.
Pull requests provide a formal mechanism for code review, allowing team members to provide feedback, suggest improvements, and ensure code quality before changes are merged. This collaborative process catches potential issues early and promotes knowledge sharing and collective code ownership.
Iterative Development and Continuous Deployment
Analytics as Code, powered by Git, enables an iterative development process. Rather than treating analytics as a linear, waterfall-style project, it allows for incremental improvements and rapid iteration based on feedback and changing requirements.
Git’s versioning capabilities make it easy to track the evolution of analytics assets over time. If a change introduces a bug or degrades performance, rolling back to a previous version is straightforward. This versioning also provides an audit trail, which is crucial for governance, compliance, and reproducibility.
Moreover, Git integrates seamlessly with automated continuous integration and deployment (CI/CD) pipelines. CI/CD streamlines the process of building, testing, and deploying code as it changes, ensuring that analytics models are consistently validated and deployed to production environments.
For example, when a data analyst pushes a change to a dimensional model, the CI/CD pipeline can automatically trigger a new model build, run a suite of tests to validate calculations and model performance and deploy the updated model to production if all tests pass. This automation reduces manual effort, minimizes the risk of errors, and enables faster iteration cycles.
Conclusion
By bringing the proven practices of software development to the analytics domain, AtScale’s Analytics as Code empowers organizations to develop more collaboratively, iterate more rapidly, and deliver more robust and impactful analytics solutions. It represents a fundamental shift in how we think about and practice analytics in this new and exciting time.
>> Learn more practical advice and best practices from top data leaders and technologists on how to implement a semantic layer at this year’s Semantic Layer Summit, a free one-day virtual event on April 24, 2024.
SHARE
2026 State of the Semantic Layer