This blog is part of a series on Microsoft Fabric from Greg Deckler, Vice President at a global IT services firm who leads a practice specializing in Microsoft technologies such as Dynamics 365, Power BI, and Azure. Greg is a seven time Microsoft MVP for Data Platform. He is the author of six books on analytics and Microsoft Power BI. Follow Greg on LinkedIn, X and on GregDeckler.com.
Part 2 – Fabric and Direct Lake Limitations
This is the second part of a three-part series exploring Microsoft Fabric, specifically Direct Lake, and whether or not these technologies and systems create a competitive advantage in the highly competitive data analytics market.
Introduction
In Part 1 of this series, we briefly explored Microsoft’s history in the enterprise data analytics space and provided an overview of Microsoft’s Fabric, Direct Lake, and Lakehouse technologies. This article focuses on the limitations of these technologies and the impact of these limitations on whether Microsoft will be successful in reversing its fortunes in the enterprise data analytics space, specifically with regard to competitors such as Snowflake and Databricks.
When it comes to limitations, Microsoft Fabric has many. There are so many that Microsoft’s documentation on Data Warehousing within Fabric contains a landing page for Limitations in Microsoft Fabric (Limitations – Microsoft Fabric | Microsoft Learn), which then provides links to no less than eleven other pages of limitations. These are just the limitations specific to Data Warehousing, not the other Fabric workloads such as Data Factory, Data Science, Real Time Analytics, OneLake and Data Engineering. Since it would be impossible to include coverage of such an extensive list, we will limit our discussion to limitations specific to Direct Lake and Lakehouse. The first of these limitations was introduced in Part 1.
Direct Lake Requires Import
As introduced in Part 1, Direct Lake is dependent on Fabric’s Lakehouse technology. Thus, data from source systems must be surfaced within Lakehouse before using Direct Lake. Thus, Microsoft’s rather misleading image for Direct Lake (Figure 2 in Part 1 of this series) is more accurately depicted as the following:

Figure 1: A more accurate depiction of the Direct Lake dependency chain
Now, with every complex software product, there often exist some exceptions and nuances to any stated fact. This is true with Direct Lake requiring import. This specific exception involves shortcuts.
Shortcuts
Shortcuts provide the ability to surface data within a Microsoft Fabric Lakehouse without copying the data. This would seem to deliver on the promise of Direct Lake being able to leave data in situ (the key advantage of DirectQuery) and thus eliminate any need for importing data. Unfortunately, the shortcuts are extremely limited and only support a bare minimum of data sources, OneLake itself, Amazon S3 and S3 compatible storage, Azure Data Lake Storage Gen2, Dataverse, and Google Cloud Storage as shown in Figure 2:
Figure 2: Supported shortcut data sources
Now, none of these data sources represent true source systems in the vast majority of circumstances. Even with linked tables, the requirement to export data to one of the supported shortcut source systems remains, as shown in the following example:
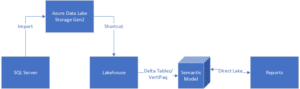
Figure 3: Using shortcuts with Lakehouse
If shortcuts supported a wider variety of source systems and those supported source systems included on-premises systems, this requirement for importing data into Fabric or other cloud-based storage would be invalidated. However, as things currently exist, with extremely few exceptions, customers desiring to use Direct Lake will be required to import data from source systems into something, whether Lakehouse/OneLake, Amazon S3 storage, Azure Data Lake Storage Gen2, etc. However, even if this is possible and makes sense, there are a number of additional limitations that must be considered.
Additional Limitations for Direct Lake
Microsoft lists the limitations for Direct Lake here: https://learn.microsoft.com/en-us/power-bi/enterprise/directlake-overview#known-issues-and-limitations
Of the roughly dozen or so limitations listed on their website, of particular interest and concern are the following:
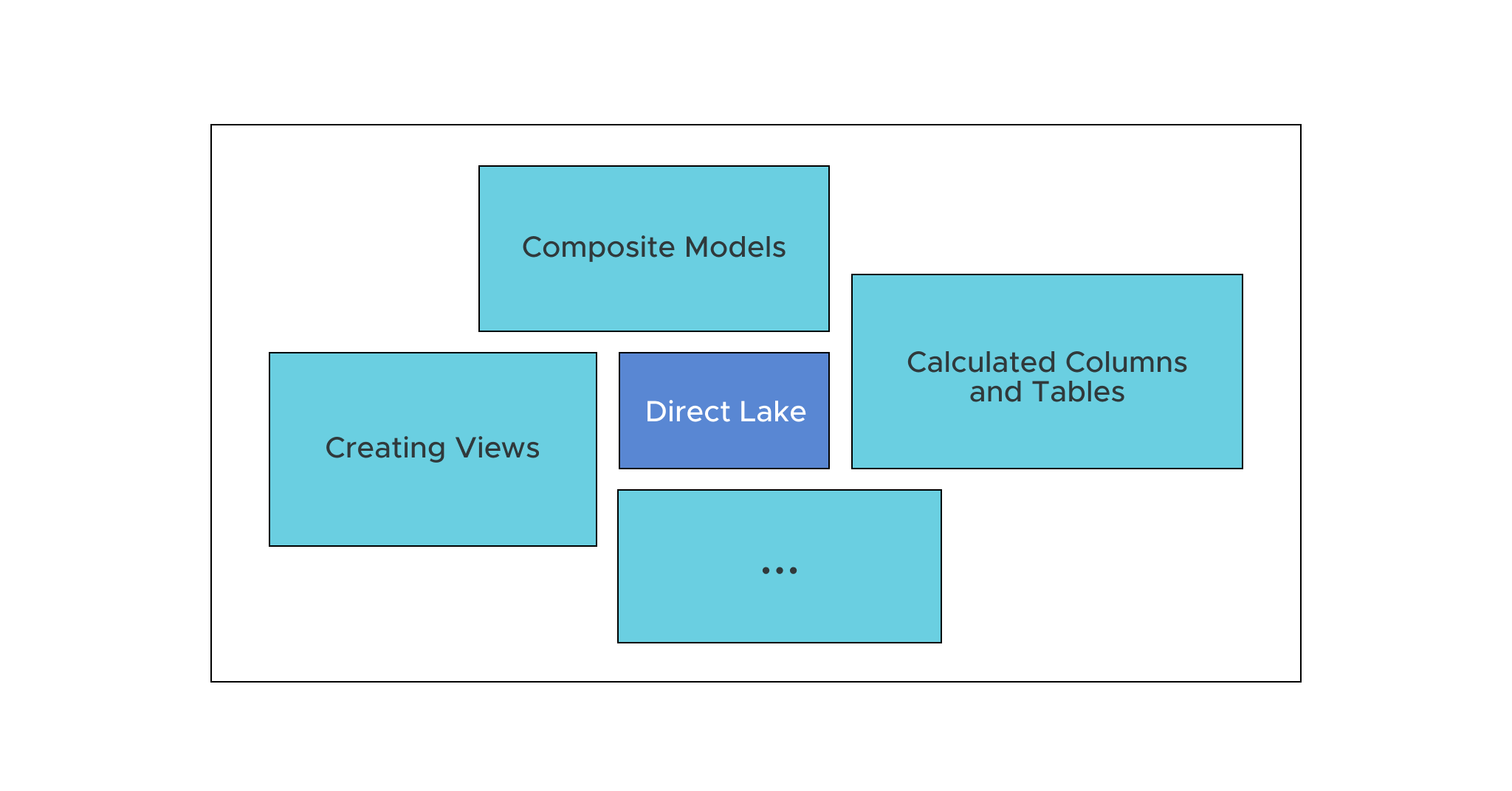
- No calculated columns or calculated tables
- Views fall back to DirectQuery mode
- Composite models are not supported
Let’s explore each of these more significant limitations in more detail.
Limitation #1: No Calculated Columns or Calculated Tables
As covered in the TPC-DS Benchmark for Power BI/Direct Lake, Lakehouse does not support calculated columns or tables. This forced AtScale to disqualify 4 of the 20 TPC-DS queries in their TPC-DS Benchmark tests.
Those who take exception to this being listed as a limitation, state that it should not matter, or even some Microsoft MVP’s that go as far as to say that DAX-calculated columns should never be used. Many of these individuals quote Roche’s Maxim of Data Transformation which states:
“Data should be transformed as far upstream as possible, and as far downstream as necessary.”
Roche’s Maxim of Data Transformation – BI Polar (ssbipolar.com)
However, these individuals only seem to pay attention to the maxim’s first clause and not the maxim’s second clause. There are plenty of reasons why calculated columns resulting from business logic should not be encapsulated at the data access layer or ETL layer.
In a broad sense, the separation of concerns design principle applies here, a principle that any self-respecting data engineer ought to understand. Separation of concerns is one of the guiding design principles behind data warehouse design, i.e., fact tables should contain only measurements, and dimension tables should only contain descriptive information about those measurements.
Calculated tables are also quite common, especially in row-level-security (RLS) scenarios. In such scenarios, it is common to have an aggregated table that summarizes and aggregates the detailed information so that users can still make broad comparisons between categories without having access to the detailed information.
It should also be noted that the inability to create calculated columns or calculated tables is two-fold. Not only does Lakehouse not support calculated columns and tables, but calculated columns and tables cannot be added to the Power BI semantic model generated by the Lakehouse. This means that powerful features for embedding business logic, such as Power BI’s grouping and binning feature, are entirely unavailable since Power BI’s grouping and binning feature utilizes calculated columns.
Regardless of any logical arguments, the final nail in the coffin for this debate is that Microsoft lists this as a limitation. Interestingly, the release plan for Microsoft Fabric Data Engineering does not include plans for calculated columns or tables, meaning that this functionality will not exist for the foreseeable future. (What’s new and planned for Synapse Data Engineering in Microsoft Fabric – Microsoft Fabric | Microsoft Learn)
There is one exception to “no calculated columns” in Lakehouse, however, and that pertains to views.
Limitation #2: Views Fall Back to DirectQuery Mode
Creating views in Lakehouse does allow the ability to create calculated columns and, by extension, calculated tables. However, views are not supported by Direct Lake, and thus, queries accessing views fall back to using DirectQuery. Again, while listed as a limitation, Microsoft seemingly has no plans to address this limitation in the foreseeable future, at least according to the Microsoft Fabric Release Plan cited above.
Limitation #3: Composite Models Are Not Supported
Another significant limitation of Direct Lake is its inability to be mixed with other types of tables, such as Import, DirectQuery, or Dual. This means that not only must all tables come from a single Lakehouse or Data Warehouse, but composite models are also not supported.
This is a significant limitation as composite models were received with great fanfare from enterprise users of Power BI. In fact, various technical experts in the field heralded composite models as a “milestone” within the business intelligence space that supposedly created a huge gap between Microsoft and its competitors in the enterprise data analytics space. Thus, it seems counter-intuitive that such an important enterprise feature is lacking from the new technologies within Microsoft’s new enterprise data analytics offering, Fabric.
However, there is some saving grace in that the semantic models created by creating a Fabric Lakehouse or Data Warehouse can be used to create derivative composite models within Power BI Desktop. In other words, one can create a Live or DirectQuery connection to the semantic model that leverages Direct Lake published to the Power BI Service.
Conclusion
Customers looking to leverage Direct Lake within their enterprise analytics solutions are faced with a minefield of significant limitations that impact the ability of Direct Lake to service such analytical workloads. Rather than focusing on limitations, the possible use case for leveraging Direct Lake within enterprise analytic workloads can be stated thusly:
Scenarios where all required data can be persisted within a single Fabric Lakehouse or Data Warehouse where no calculated columns or tables are required, do not require relationships based on DateTime columns, do not require complex delta table columns types such as Binary and Guid, do not require many-to-many relationships, do not have string columns with values exceeding 32,764 Unicode characters, do not have ‘NaN’ (Not a Number) values, and are not part of any embedding scenario that relies on embedded entities.
In addition to the rather limited usage scenario presented above, it must be stressed that Direct Lake is not a replacement for import or DirectQuery, but rather something to be used in specific scenarios. If a semantic model can be built using imported tables, that semantic model will out-perform Direct Lake and, in fact, building out the same semantic model using Direct Lake simply complicates the solution unnecessarily. Similarly, Direct Lake is not real time like DirectQuery and generally does not provide the benefits of DirectQuery in terms of leaving the data in situ within source systems. Thus, Direct Lake really only applies to maybe 2% of problematic semantic models and even then it is likely that only a small fraction of that 2% will not be excluded by Direct Lake’s current limitations.
Given this limited scope of applicability, it is difficult to see how Fabric and Direct Lake are game-changing for Microsoft in the data analytics space. However, this subject will be explored in greater detail in the final blog article in this series.
SHARE
How Does Power BI / Direct Lake Perform & Scale on Microsoft Fabric