What is a Cloud Data Warehouse?
A cloud data warehouse is a database delivered in a public cloud as a managed service that is optimized for analytics, scale and ease of use.
Cloud native data warehouses like Snowflake, Google BigQuery, and Amazon Redshift require a whole new approach to data modeling. Unlike their traditional relational predecessors like Oracle, Teradata and Netezza, cloud data warehouses are optimized for full table scans, not joins. This difference has huge implications for scale and performance as you look to migrate to these cloud native, managed database services.
What’s Different from a Traditional Data Warehouse?
There are a lot of similarities between a traditional data warehouse and the new cloud data warehouses. For example, in both implementations, users load raw data into database tables. And, of course, in both cases, SQL is the primary query language. However, there’s a major architectural difference. The new cloud data warehouses typically separate compute from storage. This means that compute resources are allocated on demand versus statically. Since compute is ephemeral, cloud data warehouses typically store their data on separate resource like Amazon S3.
Given this architecture, the cloud data warehouses prefer to scan data in bulk whereas traditional relational data warehouses can take advantage of indexing and hash joins pretty effectively. The net-net is that data models that require lots of indexing and joins may suffer in the new cloud data warehouse world. As such, the star schema, a data model that depends on joins and a stalwart in the traditional data warehouse world, is problematic in the new cloud world order.
Things Look Cloudy for the Star Schema
The star schema was born out of necessity. As database management systems moved beyond OLTP workloads and into decision support and analytics use cases, a new way of organizing data was required. The grandfathers of relational data modeling, Bill Inmon and Ralph Kimbal, popularized the star schema: fact tables surrounded by dimension tables. The star schema focused on data “normalization” with a priority of eliminating data duplication. After all, data storage was many times more expensive and scarce back then, so the star schema made sense. As a result, the relational and MPP database makers focused on creating join efficient query optimizers to support a large number of fast table joins.
In the late 2000s, the data lake was born. Data storage costs dropped by orders of magnitude as commodity disks became the de facto way of storing data. On top of cheaper storage, data platforms like Hadoop delivered performance and scale by performing full table scans in parallel used a “shared nothing” architecture. While this delivered huge scale and performance improvements on “flat” data, queries requiring joins suffered.
As it turns out, the cloud data warehouses look very much like these data lake platforms: “fast on flat” and ”slow on joins”.
Nest in the Cloud
So, if joins and star schemas don’t work in the new world, how are we supposed to scale out our analytical queries on data lakes and cloud data warehouses? The answer to use “nested” (or non-scalar) data types like JSON, XML, key-value pairs, arrays or map fields to avoid table joins altogether. This means (Ralph, plug your ears) de-normalizing data and repeating values. Google BigQuery does an amazing job at handling nested data in their engine. Here’s a simple example that demonstrates the old and new way in Google BigQuery:

Figure 1: The “Old” way (a star schema)
Notice that we need to join the “sales” fact table to the “product” dimension table to get the results we need. For large tables, this is a very expensive operation.
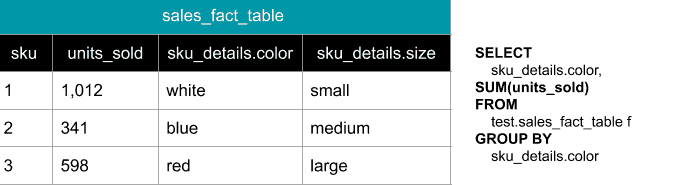
Figure 2: The “New” way (using nested data types)
In the second example, using Google BigQuery’s RECORD field type, we are able to store the product details in the same table as the facts. This eliminates the join and makes queries lightning fast. What happens if the product details change? I would argue that the “new” way of expressing this data is more accurate since this structure reflects the product details at the time of the transaction. This eliminates the need for dealing with slowly changing dimensions. You can read more about Google BigQuery’s nested data types here.
Flex Your Data
With advancements of nested and non-scalar data types, the era of hard and fast schemas is coming to an end. When I was running data pipelines for Yahoo!, just adding a new column for my analytics users meant a 4-6 week engineering effort. Why so long? I had to (1) modify my ETL jobs to include the new data, (2) change my Oracle data warehouse loading scripts, (3) add the column to my Oracle data warehouse schema including all the downstream aggregations, (4) alter my SQL Server Analysis cube and then (5) rebuild the cube. On top of all that, it took 7 days of 24×7 processing to rebuild my cubes! Ouch.
That horrific process is what we now call, “schema on write”. Given the relational databases of the time, physical columns were the only way to load data. Now with nested and non-scalar data type support, we can take a much more flexible approach: “schema on read”. That means we can add new elements to our data structures (think JSON, XML or those BigQuery record fields) and wallah, the new data is ready to query (read). Now all we need is for our BI and AI tools to discover and expose this new data without any manual intervention. Uh oh.
Next Steps: How AtScale Can Help
You will probably agree that these new data model advancements for data lakes and cloud data warehouses are a game changer. However, the existing BI and AI toolsets are really not geared to take advantage of these new innovations. They expect to see data in a traditional star schema, in fixed rows and columns. As a result, most people bring their star schemas with them into the cloud and are disappointed with their performance and agility as a result.
Enter the AtScale platform. AtScale’s accelerated query structures will readily accept your existing star schemas and optimize them automatically for the data denormalization and full table scans these data platforms prefer. If you want to take advantage of these new nested data types (and you should), AtScale has you covered there as well. We built AtScale with these new data model innovations in mind so our modeling tools and query optimizer take advantage of these new data warehouse capabilities.
Whether you’re old school or new school, rest assured that leveraging AtScale’s Universal Semantic Layer will give you the cloud boost you hoped for without the disruption of redesigning your data models or throwing out your existing BI and AI tools.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics