In my last blog, I introduced the Data & Analytics Maturity Model to help organizations evaluate where they fall on the analytics maturity scale. In this blog, I’ll discuss how to create a data-driven decisions “flywheel” to super power your organization’s ability to use data in every decision you make. I’ll also talk about the importance of investing in the right tools and processes that will serve as the “grease” to making your analytics flywheel spin.
The Data & Analytics Flywheel
Amazon is obviously a great success story and their leadership principles are admired by many across a variety of industries. The Amazon Virtuous Cycle is a strategy that leverages a great customer experience to drive traffic to the platform and third-party sellers. This in turn improves the selection of goods to further lower Amazon’s cost structure so it can decrease prices, which then spins the flywheel. This is the Amazon Flywheel.
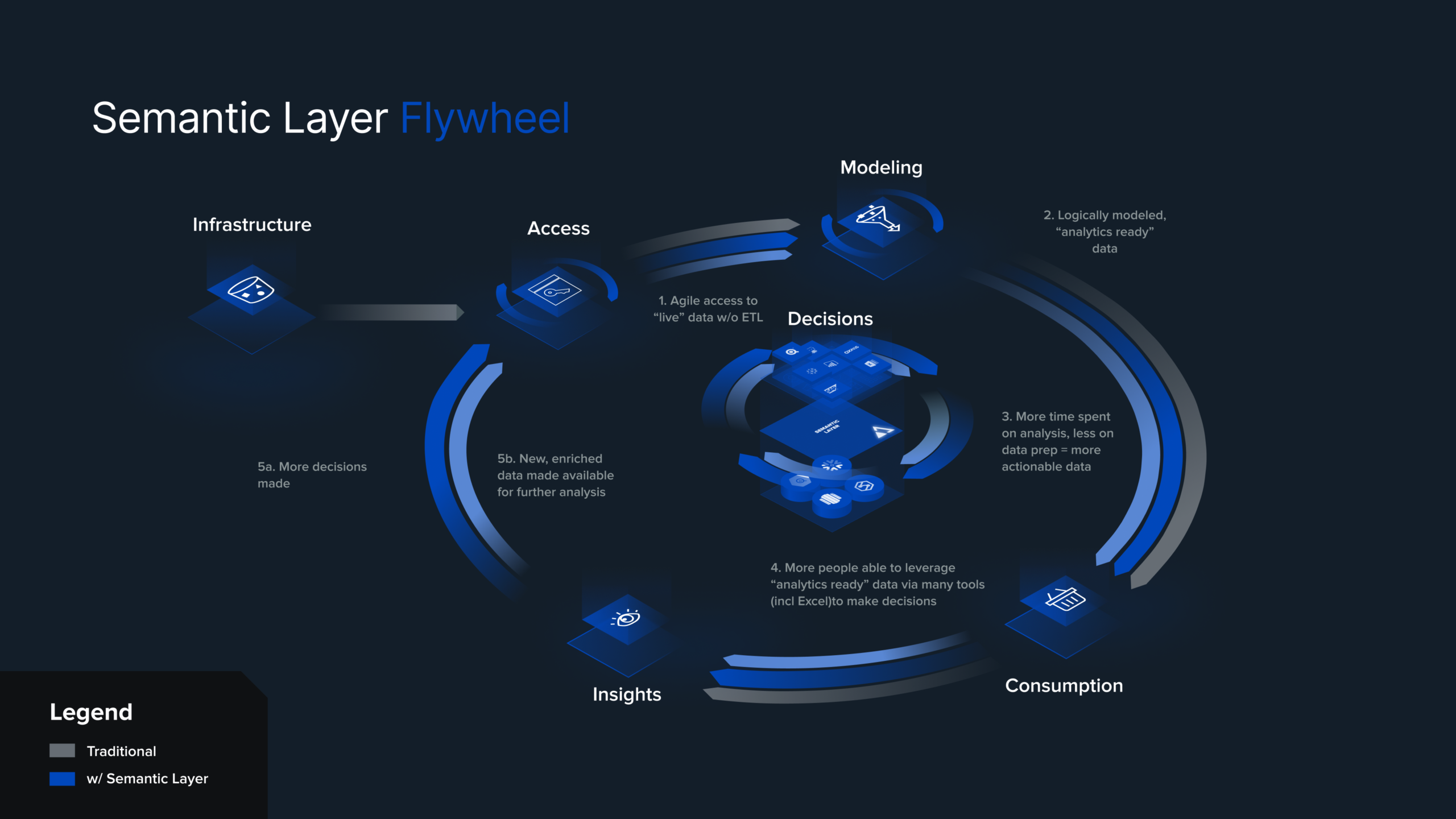
This virtuous cycle principle can also work as a strategy for accelerating data-driven decisions in your organization. The illustration below explains how this flywheel effect can drive more, higher quality data to analyze and, most importantly, smarter decisions.
Image 1: The Data & Analytics Flywheel
Now that we can see how this virtuous cycle can work, let’s dive into the necessary ingredients for making our flywheel work.
The Role of the Semantic Layer
What is a “semantic layer”? I still haven’t found a better written definition than that of Wikipedia’s:
“A semantic layer is a business representation of corporate data that helps end users access data autonomously using common business terms. A semantic layer maps complex data into familiar business terms such as product, customer, or revenue to offer a unified, consolidated view of data across the organization.”
This just about says it all. A semantic layer is critical because it creates a logical view of your data. By translating raw, physical data into business-friendly terms, a semantic layer creates “analytics ready” data, making data accessible to an audience beyond data engineers and analytics experts. By making data consumable by everyone in an organization, the semantic layer becomes the “grease” for the flywheel, making it spin easier and faster.
While you can find semantic layers embedded in many BI tools, it’s critical to separate the semantic layer from the data consumption layer to truly achieve a flywheel effect. Otherwise, in a multiple consumption tool environment (most organizations), you are likely to have several competing semantic layers, which defeats its value in providing consistent, governed access to data. It’s therefore important to consider the semantic layer as an independent, key component of your analytics stack, as depicted below.
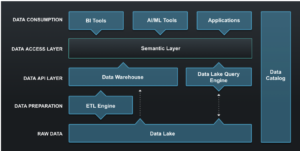
Image 2: The Modern Cloud Analytics Stack with a Semantic Layer
Besides serving as a single source of truth, the independent semantic layer also insulates the organization from future technology changes, including new data platforms and consumption tools. By decoupling query tooling from the physical data platform, you can effectively “future proof” your analytics stack. Even better, the semantic layer also hides the location and format of data from users – whether the data lives in a data warehouse, data lake or SaaS applications. This makes finding and accessing data trivial for all users, freeing them to make more decisions with less data wrangling. All of this is important to unlocking the value of analytics for all – starting with data literacy.
The Importance of a Data Literacy Program
What is data literacy? Maurice Lacroix, BI Product Owner for Bol.com, defines data literacy as the ability to read, write and speak data. I love this definition. Bol.com, a major online retailer based in the Netherlands, implemented a comprehensive data literacy program that requires its data consumers to take a series of courses to advance their data literacy skills along three levels of maturity.
The training programs helps users to:
- Read Data: Analyze & understand KPIs and other business drivers
- Write Data: Create and edit dashboards and data models
- Speak Data: Present, discuss and ask the right questions
Bol.com went beyond just teaching users on how to use tools – they teach users how to think data. Besides investing in programs and processes, technology can help with data literacy as well. A good enterprise data catalog can help to document business terms, create a data inventory and help manage data quality. The analytics flywheel spins faster by having a larger audience of informed and confident users. The next step is thinking about data as a product.
Data as a Product
Traditionally, most organizations think of data as a cost of doing business. After all, you need to provision and pay for storage and servers to manage an enterprise’s data, right? This is backwards thinking in my opinion.
Our best customers don’t think of data as a cost of doing business, but rather, they consider data as a strategic asset. These organizations treat data as a product. That means data is on an equal footing as their core products and services. By treating data as a product, they mimic the same organizational structures as their core products and services to deliver “data as a service” to their employees and partners. This means data product managers work with their customers (internal and external) to release new data products and services to drive self-service analytics. The goal is to allow more users to make data-driven decisions. By delivering higher quality data, more frequently and reliably, the most mature analytics organizations “grease” the flywheel.
How to Create a Data-driven Decisions Flywheel
In my Data & Analytics Maturity Model post, I described the six critical capabilities involved in the analytics tool and process chain. In this next section, I will map these capabilities to our flywheel and discuss how mastering each capability is key to making our flywheel spin faster.
Data
Of course we have to start with the data. To enable a flywheel, data needs to be stored in a form that’s accessible by a variety of query languages and APIs. In other words, data needs to be reachable in situ in order to provide live, up-to-date access for analytics consumers.
Access
Besides making data available via ETL-driven data pipelines, it’s imperative that data is accessible via a “live” interface to power an analytics flywheel. Data virtualization is a key technology for providing a real time (or near real time) view of data to support the most demanding analytics use cases that power our analytics flywheel.
Model
I explained the importance of the semantic layer above. To summarize, a logical model of an organization’s physical data is crucial in making data easier to understand and use by a wide range of users. In particular, a dimensional data model tends to provide the most business- friendly interface and supports the widest range of consumption tools. By making data consumable by more users, we create a larger audience making data-driven decisions to power our analytics flywheel.
Analyze
By freeing users from the time-consuming drudgery of data engineering tasks (wrangling and modeling data themselves), the semantic layer allows users to spend more time applying data to make decisions. Coupled with data literacy, more users spending more time on making informed decisions spins our flywheel faster.
Consume
Freedom to choose the best data tool for the job is key to driving more consumers to use data to make decisions. The independent semantic layer makes this possible by delivering consistent, governed data access to a variety of tools and applications. Some users may prefer using Excel for their analytics, others a BI tool like Power BI or Tableau. Data scientists may prefer a Jupyter notebook. By allowing users to leverage the tools they are most proficient in, we spin the flywheel faster through more productive users making more, data-driven decisions.
Insights
Now we arrive at the good part: turning data into meaningful insights. With our flywheel spinning, we now have (1) more users, (2) that are more productive, (3) spending more time on analytics and less on data wrangling, (4) using the tools of their choice, to make more decisions. Even better, more data-driven decisions begets even more data, generated from the output of AutoML and machine learning tools, which feeds right back into our virtuous cycle. Our flywheel is now spinning.
Summary
I hope you can see how to create your own data and analytics flywheel to move your organization to the highest level of analytics maturity. By investing in a semantic layer, data literacy and a “data as a product” philosophy, you can increase your organization’s velocity and make everyone in your organization a data-driven decision maker.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics