This blog is part of a series on Microsoft Fabric from Greg Deckler, Vice President at a global IT services firm who leads a practice specializing in Microsoft technologies such as Dynamics 365, Power BI, and Azure. Greg is a seven time Microsoft MVP for Data Platform. He is the author of six books on analytics and Microsoft Power BI. Follow Greg on LinkedIn, X and on GregDeckler.com.
Part 1 – Betting on Fabric and Direct Lake
This is the first part of a three-part series exploring Microsoft Fabric, and specifically Direct Lake, and whether or not these technologies and systems create a competitive advantage in the highly competitive data analytics market.
Introduction
Microsoft has a long history in the data analytics market. However, the last decade saw significant changes and challenges for vendors in this market, from the rise of “big data” to cloud computing, the highly competitive data analytics market became even more competitive as new vendors and technologies entered the fray. Responding to these market pressures, Microsoft adapted its SQL Server technology and created a Massively Parallel Processing (MPP) on-premises appliance called Parallel Data Warehouse (PDW). Later, this appliance was rebranded as Analytics Platform Service (APS) and then subsequently adapted to the cloud as Azure SQL Data Warehouse circa 2016. In 2020, Microsoft then introduced Synapse Workspaces which included analytics capabilities that extended beyond data warehouses.
While Synapse is a capable platform that includes data ingest capabilities via Azure Data Factory, data lake capabilities via Spark databases, Apache Spark for machine learning and data engineering and, of course, SQL data warehouses, by most measures, it was not particularly successful in the market. In particular, relative newcomers, Snowflake and Databricks both competed for the same opportunities as Microsoft. By all accounts, Synapse tended to come up short when going head-to-head with Snowflake and Databricks. Thus, in 2023, Microsoft decided to pivot yet again with the creation of Microsoft Fabric.
Microsoft Fabric continues the development of Microsoft’s data analytics platform, evolving and merging Synapse and Power BI workloads within a single data analytics platform. While many of the features in Fabric are straight lift-and-shifts from Synapse, some of the features and functionality are evolutionary or even potentially revolutionary. In particular, Direct Lake is a particularly intriguing feature.
Microsoft describes Direct Lake as “groundbreaking” technology, a new semantic model storage mode that is a “perfect” mix of DirectQuery and import modes. But can “groundbreaking” and “perfect” technology sway the tide of Microsoft’s fortunes within the data analytics market and help it keep competitors like Snowflake and Databricks at bay? That is the question we will explore in this three part series.
What is Fabric and Direct Lake?
Microsoft describes Fabric as “an all-in-one analytics solution for enterprises”. Figure 1 shows that Fabric covers data warehousing, data engineering, integration (data factory), data science and machine learning, real-time analytics and traditional Power BI workloads.
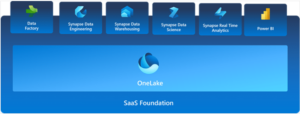
Figure 1: Microsoft Fabric Overview (credit Microsoft: What is Microsoft Fabric – Microsoft Fabric | Microsoft Learn)
As clearly noted in Figure 1, the majority of these workloads are simply Synapse workloads or evolutions of Synapse functionality and all of these workloads sit upon a foundational data lake called OneLake, which provides a single location for organizational data. More specifically, Synapse maps to Fabric roughly as follows:
- Azure Data Factory = > Data Factory
- Synapse SQL => Synapse Data Warehousing
- Apache Spark for Azure Synapse => Synapse Data Science
- Data Explorer => Synapse Real Time Analytics
- Data Lake => OneLake
- Various => Synapse Data Engineering
The data engineering area seemed to see the most investment in the evolution of the platform and includes a particularly notable feature called Direct Lake. The concept of Direct Lake is that data can be loaded directly from the lake (OneLake) and surfaced as an Azure Analytics cube, which is natively accessible as a semantic model by Power BI.
Microsoft describes this as a perfect blend of DirectQuery and import modes providing all of the advantages of both with none of their disadvantages. The advantages of DirectQuery are that data can remain in source systems, data is real time, and DirectQuery can handle large volumes of data. However, DirectQuery can be slow. Conversely, import mode is fast but data must be moved, data tends to be more stale, and import mode only handles relatively small data sizes. Microsoft’s classic image for describing Direct Lake is shown in Figure 2:
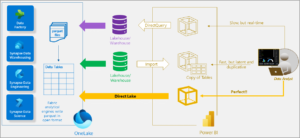
Figure 2: Direct Lake Overview (credit Microsoft: Learn about Direct Lake in Power BI and Microsoft Fabric – Power BI | Microsoft Learn)
At first, this may seem like a game changing ability, the ability to leave data at rest like DirectQuery (ROLAP) but with the querying speeds of import (MOLAP). In essence, a hybrid mode (HOLAP). In fact, the Direct Lake technology itself is rather advanced and interesting.
Import mode semantic models utilize a proprietary file format called IDF for storing VertiPaq data. VertiPaq serves as the in-memory, columnar compression storage engine for Analysis Services tabular instances. On the other hand, the Fabric engine loads delta tables, which are stored in the parquet file format instead of IDF, and then transforms this data into compatible Analysis Services data structures. Moreover, the v-order algorithm organizes the data in a manner similar to the native VertiPaq engine, aiming to enhance compression and query performance. Conceptually, an in-memory instance of a semantic model is loaded into Fabric, which provides similar performance as import mode semantic models with the ability to “fail over” to DirectQuery if needed.
Unfortunately, the image, as well as the wording that Microsoft uses to describe Direct Lake can be a bit misleading. One could easily get the impression that only OneLake and Power BI are required to use Direct Lake. However, the reality is that Direct Lake functionality is dependent upon Fabric’s Lakehouse technology.
Enter the Lakehouse
The concept of a data lakehouse is fairly recent, circa 2020. In short, data lakehouses seek to combine aspects of both data lakes and data warehouses, providing the ability to flexibly ingest copious amounts of raw data like a data lake but with the ability to perform ACID (atomicity, consistency, isolation, durability) transactions like a data warehouse. Fabric’s data lakehouse is simply called Lakehouse, and in order to use Direct Lake within Fabric, one must first create a Lakehouse. This is where Direct Lake’s “perfect” complexion starts to develop some warts.
One of the key advantages of DirectQuery is the ability for data to remain in situ. However, in order to use Direct Lake, the data must first reside in a Fabric Lakehouse. Since Fabric and Lakehouse are both new, no data exists in them today. This means that organizations with existing data warehouses and data stores in cloud-based and on-premises systems will need to migrate that data (copy) from their existing systems into a Fabric Lakehouse. While these sorts of data migrations can be costly and time consuming, perhaps even more costly and time consuming is that there is a high likelihood that existing, ongoing ETL (extract, transform, load) packages that load data into the existing data systems will likely need to be completely reengineered.
Fabric’s Lakehouse provides four different mechanisms by which data can be loaded into the lakehouse:
- Upload
- Dataflows
- Pipelines
- Notebooks
Microsoft notes that the first two options, upload and dataflows should only be used for small amounts of data. This was confirmed in testing as the upload feature was incapable of handling a 100GB file and dataflows were similarly incapable of loading 500 million rows.
Pipelines are based on Azure Data Factory and can handle large amounts of data. However, pipelines by themselves are ill-suited to complex data transformations which leaves us with notebooks for ingesting and transforming large amounts of data.
Unlike dataflows and pipelines that provide a suitable graphical user interface (GUI) accessible by both data professionals and more casual users, notebooks are purely code, supporting PySpark, Scala, Spark SQL, and SparkR, languages that are likely unfamiliar to the vast majority of the population and, in particular, the Power BI user base. That said, these languages will likely be familiar to data professionals within enterprise organizations since Snowflake and Databricks support similar languages and data loading schemes.
Conclusion
Microsoft is heavily betting on Fabric and Direct Lake to reverse its fortunes in the data analytics market. With so many large players such as Amazon, Google, IBM, SAP, and Oracle in the data analytics market, Microsoft is also under pressure from newer competitors, such as Snowflake and Databricks. Fighting a losing battle, Microsoft pivoted and leveraged its highly successful product, Power BI to rebrand and refactor its Synapse Analytics platform, hoping to leapfrog its competition in capabilities and begin to acquire market share, or, at the very least, stave off increased encroachment from competitors such as Snowflake. At the core of this approach lies a pioneering technology known as Direct Lake, which aims to enhance analytics capabilities by facilitating the querying of vast datasets. It achieves this by enabling data to remain in situ, thereby granting real-time access to the most up-to-date data, all while delivering speeds that were previously attainable only through import mode methods. Unfortunately, “in situ” currently only means stored in a Fabric Lakehouse requiring organizations with existing systems to suffer costly and time-consuming migration costs in order to leverage the technology. In addition, the direct dependency on Fabric Lakehouse exposes other limitations of the platform that detract from the capabilities of Direct Lake, limitations that we will explore in Part 2 of this three-part series.
SHARE
How Does Power BI / Direct Lake Perform & Scale on Microsoft Fabric