This is the fourth blog in my blog series, The Semantics of the Semantic Layer, where I describe the seven core capabilities of a semantic layer. In this blog, I will dive deeper into the virtualized data preparation that makes expressing business processes and calculations in a data model possible without physical data movement.
As a reminder, the following diagram shows the seven core capabilities for a semantic layer. This blog will focus on “Data Prep Virtualization”, highlighted in red:

For a semantic layer to function, it must be capable of mapping business functionality into a semantic model. Virtualized data preparation makes it simple and easy for a subject matter expert (SME) to write formulas and expressions to transform raw data into business information. Data virtualization makes it possible to implement these transformations without physically moving data. The combination of data virtualization and a powerful calculation engine means that most data pipeline work can be integrated into the semantic data model, rather than a separate process.
Openness
Data platforms, especially cloud data platforms, have come a long way from their origins as relational databases. Modern cloud data platforms allow customers to use custom SQL to store and access nested, semi-structured data and extend their platforms’ functionality with user-defined and custom aggregation functions. With a near constant flow of new, powerful functionality, it’s critically important that a semantic layer platform supports native data platform dialects for defining data transformation rules, calculations and expressions. By passing these expressions down to the underlying data platforms for execution, customers can enjoy the data platforms’ full range of capabilities and scale their data transformations by keeping them close to the data, server-side.
In the example below, we are using the native Snowflake PARSE_JSON function to find the “Sales Person” from a column containing JSON data about a sale called “SALES_INFO”:
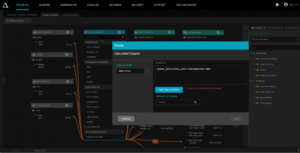
By taking advantage of the data platform’s native functionality, data modelers can leverage the syntax of their underlying data platform without needing to learn another language.
Key Takeaway: A semantic data model must support data transformation expressions in the semantic data model using the native platform’s SQL dialect.
Multipass
Sometimes a single-pass formula is not expressive enough to support calculations that combine data at different levels of granularity. For example, a weighted average calculation like “Average Interest Rate” or a ratio calculation like “Sales per Order” require data to be combined for a numerator and a denominator. In order to calculate these types of expressions, the semantic layer platform needs the ability to aggregate data first and then perform the final calculation on the aggregated results, requiring ordered operations and multi-pass queries.
The Multidimensional Expressions language, or MDX, is ideally suited for supporting these types of expressions. In addition to supporting calculations at different levels of granularity, MDX is perfect for creating time-relative and cell-based expressions like the following formula that calculates a “30 day moving average of Sales” using a Retail 445 calendar:
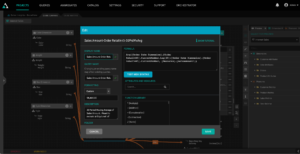
Key Takeaway: A semantic data model must support the ability to perform pre-query & post-query calculations for handling calculations that summarize data at different levels of granularity.
Virtualized
Data wrangling tools and ETL/ELT platforms are familiar to most data engineers. These tools are meant to move data from point A to point B while transforming data for the purposes of cleansing, correcting, combining or just calculating new values. For most use cases, creating new tables or files with transformed data is overkill and adds complexity to data pipelines.
Data virtualization can automate most data transformation tasks without data movement and with the added benefit of leveraging the power of the data platform for performing these transformations. By pushing calculations down to the underlying data platform without physical data movement, subject matter experts can create flexible, documented data transformations without writing complex code.
For example, in the image below, we are “cleaning” the “sales_reasons” field by replacing the NULL values with an “Unknown” string by creating a new virtual column.
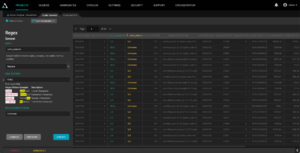
Key Takeaway: A semantic later platform should support inline data transformations using direct queries without data movement or creating copies of data.
The Power of Data Prep Virtualization
Besides serving as a metrics hub, a semantic layer is a central repository for business logic and calculations. By supporting complex, multipass data transformation expressions, the semantic data model can take the place of physical ETL data pipelines. By harnessing the power of the subject matter expert, the semantic layer platform can become the digital twin of the business while avoiding dependencies on data engineers and SQL experts. In my next post, part five of eight, we’ll dive into the importance of a multi-dimensional calculation engine.
In the meantime, ff you are looking to skip ahead, I encourage you to read the white paper, “The Semantics of the Semantic Layer”.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics