Data is invaluable to an organization’s decision-making, business innovation, and cross-team collaboration. With the rise of big data and cloud data warehouses, fully-realized democratization is the next step in many businesses’ data journeys. They want to enable company-wide, self-service analytics, making massive amounts of data available and usable to all. Often, modern-day companies aim to democratize their data through techniques like data mesh, hub-and-spoke analytics management, and data virtualization.
Data democratization has the potential to create immense value for an organization. It means that every staff member—both data experts and non-experts—can build their own data products and make intelligent decisions without the data analytics team standing in the way as a gatekeeper. But thanks to semantic sprawl across the modern data analytics stack, democratization is much easier said than done.
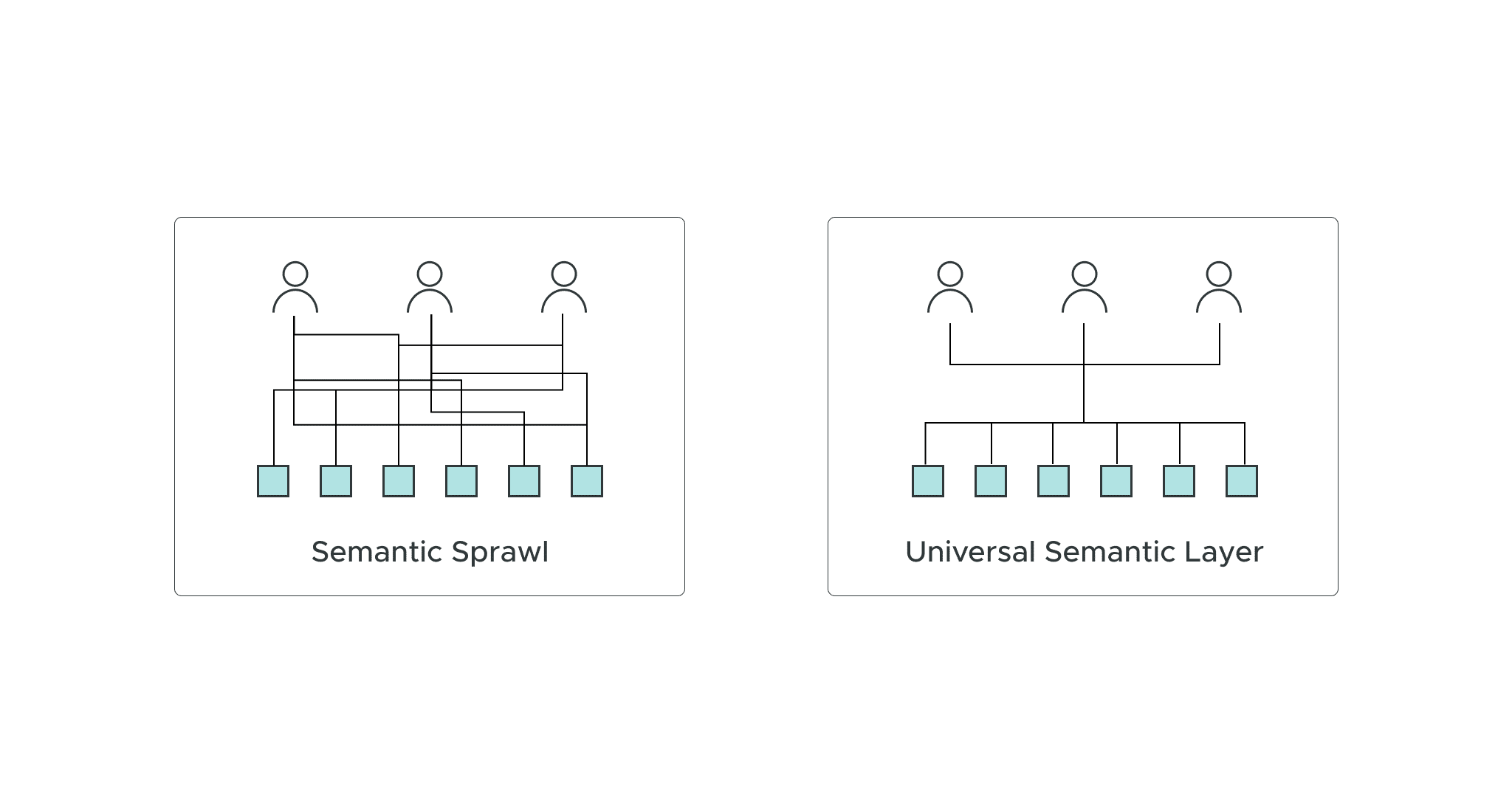
What is Semantic Sprawl?
Semantic sprawl happens when an organization unintentionally deploys several competing data definitions to describe the same key business concepts. It’s a common challenge because semantic rules are often embedded inside BI tools, reports, and dashboards. Semantic sprawl arises as isolated departments develop their own ways of defining and calculating these concepts. This issue is comparable to how human language evolves within geographic regions (think of American English as compared to British English).
For example, a customer might be defined in different terms throughout the marketing/sales cycle. They might be classified as a “prospect” by the marketing team, a “client” by the sales team, then a “counterparty” by the finance team. With these fragmented, competing definitions, it’s difficult to share data and create consistent reports such as “lead to cash.”
As semantic sprawl continues across an organization, standardizing analytics becomes very challenging. For instance, if teams already use several different ways to describe revenue, comparing numbers across different business units becomes difficult—if not impossible. Without universal consistency between definitions, it’s impossible to facilitate self-service analytics approaches.
How Does Semantic Sprawl Happen in the Modern Data Analytics Stack?
When teams use competing semantic layers to translate raw data into actionable insights, semantic sprawl is inevitable.
These competing semantic layers usually appear in the following locations within the data stack:
- Analytics tools. Teams often use the semantic layers embedded into disparate BI tools. This is a problem on two fronts. First, each BI analyst may model and define business metrics differently in their reports and dashboards, even when using the same BI tool. Next, users of different BI tools may also create competing metrics within wholly separate semantic layers that are specific to each tool.
- Data warehouses. Architects sometimes use a data mart to create definitions directly inside their data warehouses. While this works in theory, it’s a cumbersome way to manage business definitions in practice. A data warehouse may contain thousands of tables stored within schemas that are unsuitable for analytics. Business users often import data into their preferred BI tools to achieve acceptable query performance and create localized data silos. It leads to the same issue: semantic sprawl between analytics tools and extra data copies to boot.
- Data Pipelines. Data engineers add semantic layer logic into their ETL pipelines to transform data into a usable form. Embedding business semantics into data pipelines becomes challenging to maintain as the business scales up and data grows.
How a Universal Semantic Layer Helps
To avoid semantic sprawl, organizations can standardize on a single semantic layer as a standalone component in the modern data stack—a universal “translator” that brings consistency to metrics to every corner of the company.
As an independent layer living within the modern data stack, a universal semantic layer turns raw data into usable metrics for all business consumers regardless of their preferred consumption tools. The universal semantic layer serves as a translator without actually storing data by using metadata and data virtualization to create a logical view of technical data.
Businesses can leverage a universal semantic layer to:
- Unite BI, AI, and ML efforts across the organization with a single view of historical and predictive data.
- Replace legacy OLAP tools for delivering multi-dimensional queries on modern cloud data platforms.
- Reduce computing costs and time-to-insights by optimizing queries and transforming in real-time.
- Promote the development and sharing of business-friendly data models across every business domain.
At AtScale, we provide a universal semantic layer that fits seamlessly into a modern data stack. We aim to make analytics accessible to everyone while making lives easier for data teams.
Learn how the universal semantic layer compares to other semantic layers in our blog post Choosing the Right Semantic Layer Strategy for Your Organization’s Data Stack.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics